Conversion to time series format
For a lot of applications it is favorable to convert the image based format into a format which is optimized for fast time series retrieval. This is what we often need for e.g. validation studies. This can be done by stacking the images into a netCDF file and choosing the correct chunk sizes or a lot of other methods. We have chosen to do it in the following way:
Store only the reduced gaußian grid points since that saves space.
Further reduction the amount of stored data by saving only land points if selected.
Store the time series in netCDF4 in the Climate and Forecast convention Orthogonal multidimensional array representation
Store the time series in 5x5 degree cells. This means there will be 2566 cell files (without reduction to land points) and a file called
grid.ncwhich contains the information about which grid point is stored in which file. This allows us to read a whole 5x5 degree area into memory and iterate over the time series quickly.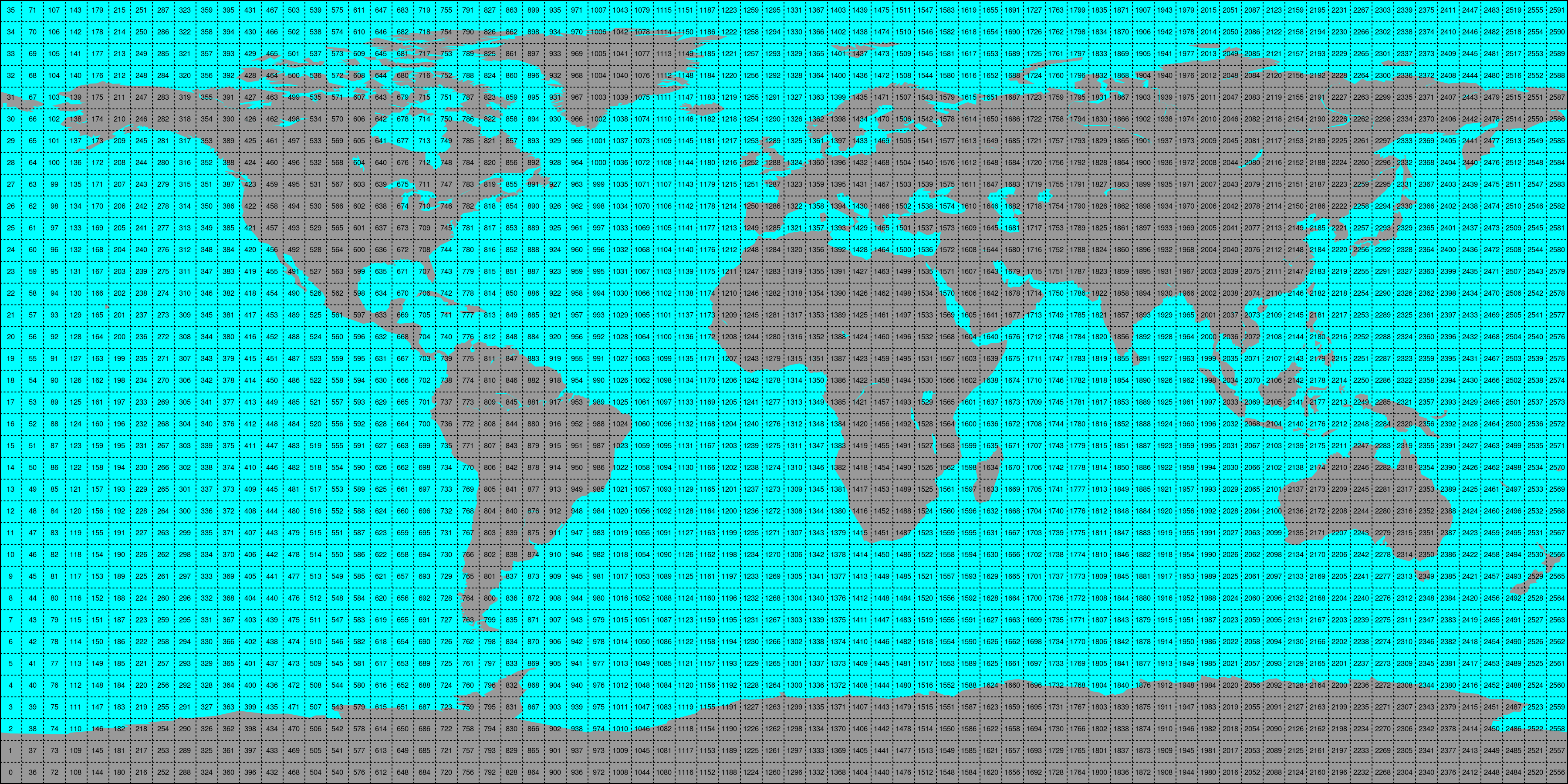
This conversion can be performed using the gldas_repurpose command line
program. An example would be:
gldas_repurpose /download/image/path /output/timeseries/path 2000-01-01 2001-01-01 SoilMoi0_10cm_inst SoilMoi10_40cm_inst
Which would take GLDAS Noah data stored in /gldas_data from January 1st
2000 to January 1st 2001 and store the parameters for the top 2 layers of soil moisture as time
series in the folder /timeseries/data.
Conversion to time series is performed by the repurpose package in the background. For custom settings
or other options see the repurpose documentation and the code in
gldas.reshuffle.
Note: If a RuntimeError: NetCDF: Bad chunk sizes. appears during reshuffling, consider downgrading the
netcdf4 library via:
conda install -c conda-forge netcdf4=1.2.2
Reading converted time series data
For reading the data the gldas_repurpose command produces the class
GLDASTs can be used:
from gldas.interface import GLDASTs
ds = GLDASTs(ts_path)
# read_ts takes either lon, lat coordinates or a grid point indices.
# and returns a pandas.DataFrame
ts = ds.read_ts(45, 15)